In the previous synthetic comparison between ebtree and cebtree it was quite clear that performance varies quite a bit between key types, key distribution, lookup-to-update ratio, and tree type. While the initial utility was fine to get a rough performance estimate, it appeared important to measure the cost per operation (insert, lookup, delete). Also, the impact of the key distribution made me want to compare how balanced trees compare, since they can sometimes be interesting as well. Thus a new tool was written ("ops-time") and stored with the previous stress utility into a new project, treebench. The utility was written so that all basic operations are defined by macros, easing the integration of various tree primitives in the comparison.
Principles
The tool generates a pre-defined number of keys whose distribution matches a specific profile. Key may be read from stdin, can be full randoms, ordered with small increments in order to match timers used in schedulers, poorly distributed randoms with long chains, or short strings; Key types may be u32, u64 or strings.
Then these keys are inserted into a tree, the timing is measured over the second half (so as not to be affected by too fast operations on empty trees), then they're all looked up, then they're all deleted, and again, the timing is taken only during the first half when the tree is mostly full.
The tests chosen here were representative of specific known use cases:
- insertion/deletion of u32/u64 timer-like keys: this is what happens in schedulers. Lookups are basically inexistent (only a first() or a lookup_ge() happens then only next() is used). Nodes are inserted when the timer is created and deleted when it's removed, most of the time without ever having been visited when this is used to store timeouts (which rarely trigger). One property of such keys is that they're groupped and inserted mostly following an ever-increasing pattern. Here we're using the small positive increments (we avoid duplicates in order to support all tree types).
- insertion/lookup/deletion of 64 bit randoms. This matches what happens in caches where hashes are looked up and stored if non-existing. Keys are normally very well distributed since deriving from a secure enough hashing algorithm. Lookup are very frequent, and if the cache has a good hit ratio, they can represent close to 100% of the operation. However in case of low hit ratio, insertion and deletion become important as well since such trees are usually of fixed size and entries are quickly recycled.
- short strings: the idea here is to have the same distribution as above with the randoms, but represented as strings. It emphasizes the cost of string comparison operations in the tree and of accessing larger nodes. This is commonly used for a few use cases: looking up session cookies (which are normally secure randoms since non-predictable), where lookups and creations are important, and they can be used to look up config elements such as UUIDs, which are created once and looked up often. In the case of haproxy for example, lookup of backend and server names is done like this. In such cases, insertion of many objects can directly impact a service's startup time, the lookup impacts runtime performance, and deletions are never used.
- real IPv4 addresses: it's known that IP addresses are not well distributed on the net, with some ranges having many servers and others many clients, as well as some addresses never being assigned, or sometimes being assigned to routing equipments, thus leaving holes. Here a sample of ~880k real IPv4 addresses was collected from the logs of a public web service, and these were used to run a test to see the impact of a different distribution. Note that the frequency of these addresses was not considered for the test, and each address appeared only once.
- real user-agents: similarly, user-agents strings are a perfect example of strings that do not vary much and have long chains in common. Often variations are only a single digit in an advertised plugin version. And such strings can be large (even if these days browsers have considerably trimmed them). The test was run against ~46k distinct user-agents collected from logs as well, ignoring their frequency, for the sole purpose of observing behaviors under such real-world conditions. The average user-agent length was 138 bytes.
All these tests will be run for tree sizes from 512 keys to 1M keys (1048576), except for real input values where the test will stop at the size of the input data. Also, when relevant (i.e. all cases but timers), the tests will also be run with multiple tree heads selected based on a hash of the key. Indeed, trees are commonly used to build robust hash tables when there's no ordering constraints, which allow to reduce the lookup cost thanks to the hash that reduces the average number of levels, while not suffering from the risk of attacks that regular list-based hash tables suffer from. The tests will be run with 1, 256 and 65536 tree heads, selected by an XXH3 hash of the key, in order to reduce the tree sizes.
Implementations under test
Three implementations were compared:
- Elastic Binary Trees (ebtree), using stable branch 6.0. This is the commonly used branch. Tree nodes consume 40 bytes on 64-bit machines. Being a prefix tree the depth depends on differences between keys and is bound by their size. Insertions are O(logN), deletions are O(1). Duplicates are supported with a O(logN) insertion time.
- Compact Elastic Binary Trees (cebtree), using the master branch (3 commits after cebtree-0.3), which is currently considered as feature-complete. Tree nodes only consume 16 bytes on 64-bit machines (only two pointers, just like a list element). Just like ebtrees, insertions are O(logN), however deletions are O(logN) since there's no up pointer. Duplicates are supported and inserted in O(1) time.
- Red-Black tree (rbtree), using pvachon's implementation. This one was found to be of good quality, clean, easy to integrate and a good performer. The tree node consumes 24 bytes (3 pointers), thus a generic approach takes 32 bytes due to alignment (though by having key-specific types it's possible to store the key or a pointer to it inside the node). Insertions are O(logN), and deletions are an amortized O(logN) that's closer to O(1) with a higher cost due to tree rebalancing that doesn't happen often but that can be costly if multiple nodes have to be rebalanced.
Test results
The tests were run on an Arm-v9 device (Radxa Orion-O6) and on a recent Xeon W3-2435 (8 Sapphire Rapids cores at 4.5 GHz). The patterns were mostly identical on both devices, showing different inflexion points due to cache sizes, and higher general costs for the Arm running at a lower frequency.
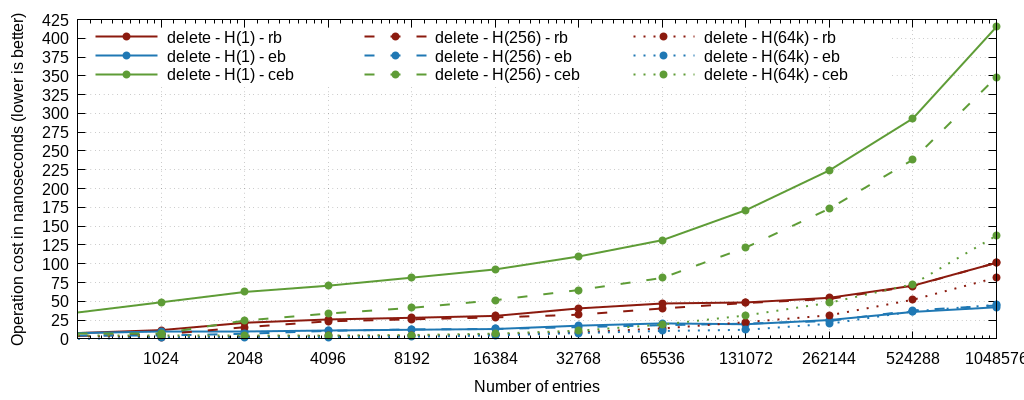
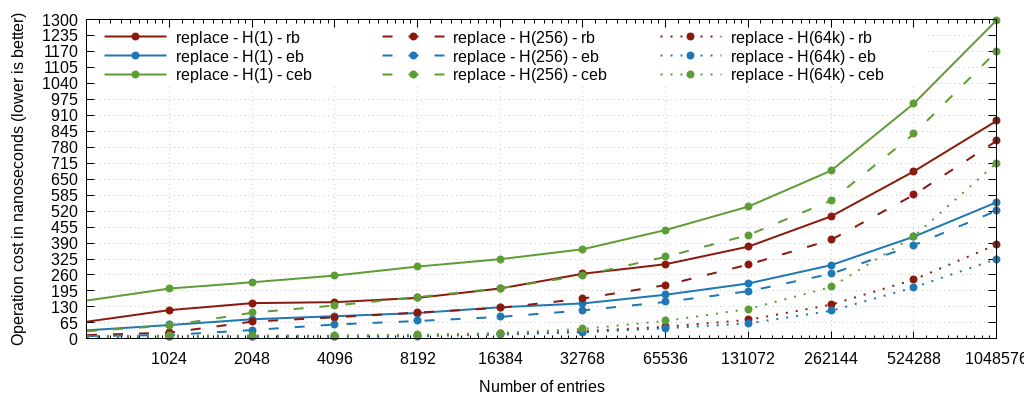
We're showing graphs for insert time, lookup time, deletion time, and what we call "replace", which is in fact the sum of the deletion and the insertion, which corresponds to a node recycling in a cache, or to the only operations that matter for timers (one insertion and one deletion).
The graphs are plotted with full lines for the single-head mode, dashed for the 256-head mode, and dotted for the 65536-head mode. Just click on the images to see the details.
1- Timers
Here we're essentially interested in the last "replace" graph. It perfectly illustrates something that we had observed in haproxy a long time ago (in version 1.2) when rbtrees were being used for the scheduler: the cost of rebalancing and the resulting imbalance are overkill for such regularly distributed keys. Here ebtrees are 3x faster, which is approximately in line with observations made by then when replacing them in haproxy. Some instrumentation was made on the tree traversal code to measure the number of levels, and it appears that in this specific case, ebtrees are shorter than rbtrees. Indeed, rbtrees try not to rebalance too often to amortize the cost, and end up guaranteeing that no branch will be more than twice as long as any other one, which means that it's possible to end up with 2*log(N) levels in the worst case. And for keys that are constantly renewed, this is exactly what happens. With ebtrees on the opposite, the good distribution ensures that the tree depth is also mostly equal between branches, and roughly matches log(N)+1..2 most of the time. It's interesting to note that except for the removal where cebtrees are much more expensive than the two others, cebtrees are as fast as ebtrees for insertion and as slow as rbtrees for lookups, and end up between the two for the whole pattern. This means that in cases where timers are not under heavy stress and rbtrees could be considered to save memory, then cebtrees would in fact be both smaller and faster for this type of keys and distribution. This could concern cache or certificate expiration for example where key size is more important than raw performance.
2- 64-bit hashes
Here on randomly distributed keys, we're observing the same phenomenon as in the previous test. It took a while to figure the cause but again it's the imbalance of rbtrees vs the better balance of ebtrees on such well distributed keys that make the difference. It's also visible that insertion is faster for cebtrees than ebtrees when the tree grows (256k keys and above), clearly due to the significantly higher memory footprint of ebtrees. It's interesting to note that single-headed ebtrees here are inserted as fast as 256-headed rbtrees and follow the curve all along. It's also visible that all trees insert much faster when hashed enough, since randomly distributed keys result in properly balanced sub-trees. It's visible that using 64k heads divides the insertion time by roughly 4 for all types.
For the lookups however, cebtrees are almost as slow as rbtrees. The reason seems to be related to the need to consult adjacent nodes all along the descent, resulting in reading 3 times more data before knowing where to go, which doesn't cope well with prefetching and branch prediction. and here the rbtree and cebtree curves are mostly fused all along the tests. Hashing does considerably help but doesn't benefit as much to cebtrees as it benefits to others: even at 256 heads, cebtree lookups become the slowest of the 3. And while at 256 heads, ebtrees are much faster than rbtrees, at 64k heads rbtrees win by a small margin. It is possible that a few imbalanced chains are longer in ebtrees than the roughly balanced ones in rbtrees in this case, as there should be on average 16 keys per tree a 1M entries. But once we consider the replacement cost (since such hashed keys typically have to be recycled in caches, tables etc), then the gain is well in favor of ebtrees which can still be 30% faster in total. Overall for such use cases, it looks like ebtree remains the best choice, and that cebtrees do not make much sense, unless space saving is the primary driver.
3- short strings
For short strings, ebtrees remain faster than rbtrees to insert and lookup, by roughly 30% for insertion and 20% for lookups. One reason might simply be that we don't need to re-compare the whole string, the comparison only restarts from the current level's position. However these are typical cases where it makes sense to hash the keys (unless they have to be delivered ordered, but session cookies do not have this problem for example). In this case we see that when hashing with sufficient heads (64k), then rbtree becomes twice as fast for lookups with a steep divergence around 256k entries, very likely because again, there might exist longer chains in the resulting small ebtrees than in the similarly sized rbtrees. In all cases, cebtrees follow ebtrees, except for removal where the O(logN) deletion time increases the cost.
The conclusion on this test would be that if ordering is required, then one must go with ebtree or cebtree, which show roughly equivalent performance except for deletion where cebtrees are not good. If ordering is not a concern and topmost speed is required and hashing over a large number of buckets is acceptable in order to end up with small trees, then better go with rbtrees that will have shorter long chains on average.
4- IPv4 addresses
IPv4 address storage and lookup is much more chaotic. Due to the anticipated poor address distribution, it's clearly visible that below 256k IPv4 per tree head, lookups via ebtree are significantly faster than rbtree, and that above, rbtree is significantly faster than ebtree. This clearly indicates the existence of long chains (up to 32 levels for IPv4). Also, insertion is always faster on ebtrees even when hashing at 64k. And if that wasn't complicated enough, cebtree is always faster both for insertions and lookups (but as usual, removal is way more expensive). However, this also means that it would likely be sufficient to apply a bijective (non-colliding) transformation like an avalanche hash to the stored keys to flatten everything and get a much nicer distribution, and get back to the same scenario as for 64-bit hashes above.
So what this means is that if IPv4 keys are needed (e.g. store per-client statistics), no single implementation is better over the whole range, and it would be better to first hash the key and use it like this, provided that the hashing algorithm is cheap enough. Given that XXH3 is used with good results for hashed heads, it's likely that XXH32 would be efficient here. But overall, indexing raw IPv4 addresses is suboptimal.
5- user agents
Here the first observation is that for large mostly-similar strings, one must not use cebtrees, which are twice slower than rbtrees, both for inserts and lookups. And ebtrees are not good either, being ~10% slower to insert and ~30% slower to look up. This is not surprising, because as anticipated, user-agents only differ by a few chars, and can be long, so there can be long chains of a single-char difference, implying many more levels in the prefix trees and in the balanced tree. However, here again, if sorting is not a requirement, it could make sense to hash the inputs using a fast non-colliding hash and index the hashes instead of the raw keys. Also, all operations made on cebtrees are significantly slower, again likely due to having to fetch adjacent keys, hence increasing the required memory bandwidth.
First conclusions
Prefix trees are much more sensitive to the input keys distribution, so it is not surprising to see ebtrees and cebtrees perform much less well when facing poorly distributed keys like client IP addresses or user agents. IPv6 addresses could behave worse, even letting the client choose to create 64-deep sub-trees for their own network. However, it's not like lists, because the slowest path is quickly reached and is bounded by the key size.
When high performance on large keys is desired, better use rbtrees, or split the trees using a hash if ordering is not a requirement. In this case it can even make sense to index the hashed key instead of the key itself in order to regain a good distribution as is observed in the 64-bit hashes tests.
Compact trees were initially expected to be way slower, while it's mostly the delete operation which is slower, but overall, they perform quite well, often better than rbtrees on small keys. They suffer from large keys due to the descent algorithm that requires to XOR the two next branches in order to figure where the split bit is located, hence consuming more memory bandwidth. For cases where removals are rare and keys are reasonably small, they can be very interesting. Tests on haproxy's pattern reference subsystem (map/acl indexing) even showed a boot speedup compared to existing code that uses ebtrees, and a significant memory saving. In general, using them to look up config-level elements seems to make sense. For more dynamic keys (session cookies etc), it may depend on the expected average lookup hit ratio. And they seem to have an interesting role to play in hash tables where they could replace lists and avoid the linear performance degradation that occurs when the load factor increases. This could be a drop-in replacement using the same storage model as the lists.
Rbtrees remain good overall (which was expected, there's a reason why they've been so widely adopted), and their performance doesn't really depend on the nature of the keys. This is also why, while they are much better on large keys, they cannot benefit from certain properties such as the timers or even well-distributed small keys.
It really looks like running a non-colliding hash on inputs and indexing only that could be very interesting with all trees. One must just make sure not to meet collisions. A 128-bit hash could be sufficient (though it would double the cebtree size). Another option would be to stay to 64-bit with a keyed hash, and change the key when a collision is encountered. It would be so rare that it might make sense, but could possibly not be compatible with all use cases. And some bijective algorithms exist that will not cause collisions on inputs of their native size (avalanche, CRC etc), allowing a great input mixing without introducing collisions.
Other trees like AVL could be evaluated. Their insertion/removal cost is higher as they will try hard to stay well balanced, but these could be the fastest performers for pure lookups.
Also here we've only spoken about indexing unique keys, but sometimes duplicate keys are needed (particularly for timers). The mechanism created for cebtrees would be portable to other trees by stealing one bit in the pointers. It would add to their complexity, but could theoretically work for rbtrees, making them suitable for more use cases. The could also be adapted to ebtrees to further speed up insertion of duplicates, which exists a lot in timers.
It's also visible that all trees degrade very quickly when the data set doesn't fit into the L3 cache anymore, and cebtree even more due to the need to check adjacent nodes. And there is a double problem: not fitting means more cache misses at each level, but not fitting also means a large tree hence more levels. This explains why the performance systematically degrades very fast with the tree size: we increment both the number of levels and the risk of a cache miss at each level, making the degradation grow faster than the tree size. This indicates that trees alone are not necessarily relevant on super-large datasets (e.g. database indexing). Again that's where combining them with fast hashes can make sense.